
You can find a t-SNE plot in almost every single-cell paper. But what are the dots, colors, and axes? This blog explains how you can interpret the plot.
Single-cell RNA sequencing datasets are huge. They usually contain the expression count of thousands of genes for thousands of single cells. One of the ways to visualize the data, which often shows up in scientific papers, is the t-SNE plot.
We wrote about what t-SNE means and how it works in a different blog. Without making it too complicated, you could say that the t-SNE algorithm can make a plot from a dataset that is otherwise unplottable. t-SNE aims to capture the similarities between cells in the original dataset by placing the cells close together on a two- or three-dimensional plot. The purpose of a t-SNE plot is to help the viewer see the underlying patterns in a single-cell RNA data set. Still, misunderstanding what these plots show can lead to misinterpretations.
In this blog, we aim to guide you through the main components of t-SNE. When you look at the plot, what do you see?
Simply put, a t-SNE plot consists of three main elements: dots, colors, and axes.

What are the dots on a t-SNE plot?
In single-cell RNA studies, every dot on a t-SNE plot represents a cell.
As explained above, the location of a cell on a the plot is determined by its similarity to other cells. Similar cells are placed together, while different cells are placed further apart.
Dots with short distances between them (so dots that form these island-like clusters) represent groups of cells with similar gene expression profiles. Cells within a cluster may have similar functions in a tissue: they may be the same cell type or react identically to treatment. Different cell groups may have different functions in a tissue or may be at diverging stages of development.
There's also information in the patterns within a cluster. Cells that lie on opposite sides of a cluster are usually more different than cells that lie closer to each other.
However, t-SNE is less stringent on placing cells far apart that are very different. This means that the distance between clusters is usually meaningless. So, you cannot conclude from a t-SNE plot that groups of cells that lay far apart are indeed cell types with very different gene expression profiles. An alternative algorithm called UMAP does this more strictly. That's why UMAP plots are often used in addition to t-SNE plots in single-cell research.
What are the colors on a t-SNE plot?
You can place different color labels over the data points in a t-SNE plot. In single-cell RNA studies, researchers most commonly color the cells by cell cluster, sequencing library, quality control metrics, or specific gene expression counts.
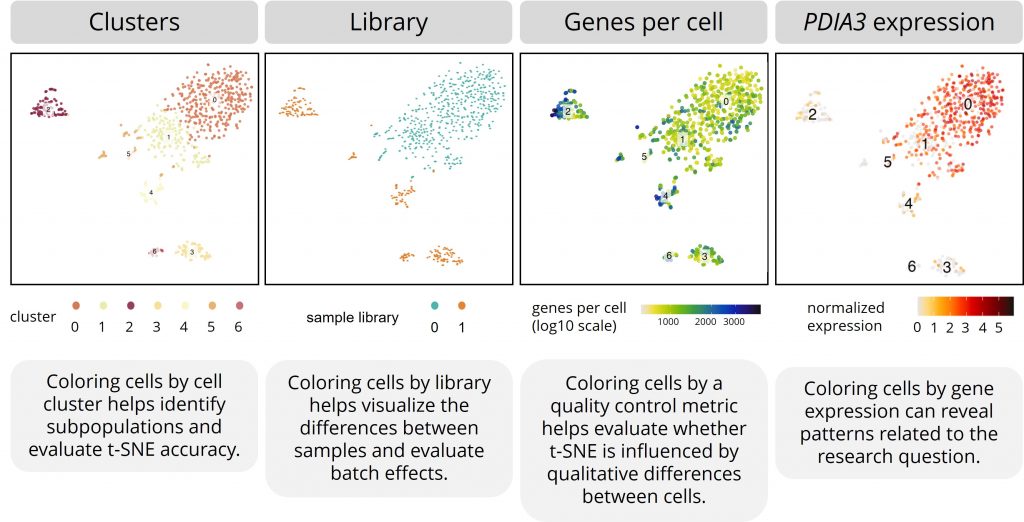
Cell clusters
Although t-SNE can visualize data to make clusters appear, most people use more accurate methods to define the cell clusters and subpopulations.
Placing color labels for the defined cell clusters over the t-SNE helps identify subpopulations more effectively and helps evaluate it's accuracy.


